浏览器的主要功能是展示网页资源,也即请求服务器并将结果显示在浏览器窗口中。
# 1. 浏览器主要功能
浏览器的主要功能,则是通过向服务器请求并在浏览器窗口中展示这些资源内容,这些内容通常包括 HTML 文档、PDF、图像等,我们也可以通过插件的方式加载更多其他的资源类型。
一般来说,我们在浏览器中会用到以下功能:
- 用于输入 URI 的地址栏
- 刷新和停止按钮,来控制当前文档的加载
- 后退和前进按钮,控制文档历史的快速访问
- 书签和收藏选项
HTML 和 CSS 规范中规定了浏览器解析和渲染 HTML 文档的方式,曾经各个浏览器都只遵循其中一部分,因此前端开发经常需要兼容各种浏览器。现在这些问题已经得到改善,同时配合 Babel 等一些兼容性处理编译过程,我们可以更加关注网站的功能实现和优化。
从结构上来说,浏览器主要包括了八个子系统:
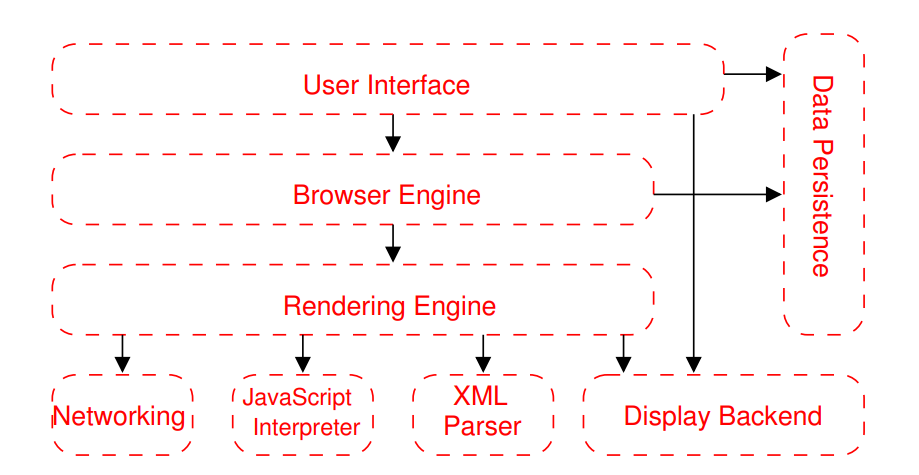
- 用户界面:包括前面提到的用户主要功能地址栏,状态栏和工具栏等
- 浏览器引擎:一个可嵌入的组件,它提供了用于查询和操作渲染引擎的高级界面
- 渲染引擎:负责显示请求的内容,比如用于对 HTML 文档进行解析和布局,可以选择使用 CSS 样式化
- 网络子系统:用于 HTTP 请求之类的网络调用,在独立于平台的界面后面针对不同平台使用不同的实现
- JavaScript 解释器:用于解析和执行 JavaScript 代码
- XML 解析器:用于解析和运行 XML 代码
- 显示后端:用于绘制基本小部件和字体,例如组合框和窗口
- 数据持久性子系统:即数据存储,该子系统在磁盘上存储与浏览会话相关的各种数据,包括书签,Cookie 和缓存
这些子系统组合构成了我们的浏览器,而谈到页面的加载和渲染,则离不开网络子系统、渲染引擎、JavaScript 解释器和浏览器引擎等。下面我们以前端开发最常使用的 Chrome 浏览器为例,进行更详细的介绍。
Chrome 多进程架构
关于进程和线程的概念,这里不多介绍,这些也都是开发需要掌握的基础内容,大家可以自行进行学习。
Chrome 使用了多进程架构,具有以下进程:
(1) 浏览器进程:控制和处理用户可见的 UI 部分(包括地址栏,书签,后退和前进按钮)和用户不可见的隐藏部分(例如网络请求和文件访问)。
(2) 渲染器进程:控制显示网站的选项卡中的内容。
(3) 插件进程:控制网站使用的插件(例如 Flash)。
(4) GPU 进程:与其他进程隔离地处理 GPU 任务。
我们知道,Chrome 等浏览器支持多个选项卡,每个选项卡在单独的渲染器进程中运行,选项卡之外的所有内容都由浏览器进程处理。其中,浏览器进程具有以下线程:
- UI 线程:用于绘制浏览器的按钮和输入字段
- 网络线程:用于处理网络请求,以及从服务器接收数据(包括 DNS 解析、TCP 建连、HTTP 建立等等)
- 存储线程:用于控制对文件的访问
同样,渲染器进程也具有一些线程:
- GUI 渲染线程:负责对浏览器界面进行渲染
- JavaScript 引擎线程:负责解析和执行 JavaScript 脚本
- 浏览器定时器触发线程:
setTimeout和setInterval所在的线程 - 浏览器事件触发线程:该线程负责处理浏览器事件,并将事件触发后需要执行的代码放置到 JavaScript 引擎中执行
# 2. 页面导航
当我们去面试的时候,常常会被问一个问题:在浏览器里面输入 url,按下回车键,会发生什么?这是个或许平时我们不会思考的问题,但在了解之后会对整个网页渲染有更好的认识。当我们按下回车键,在 DNS 解析、TCP 连接建立后,浏览器就会发起一个 HTTP 请求,我们也可以从控制台看到:
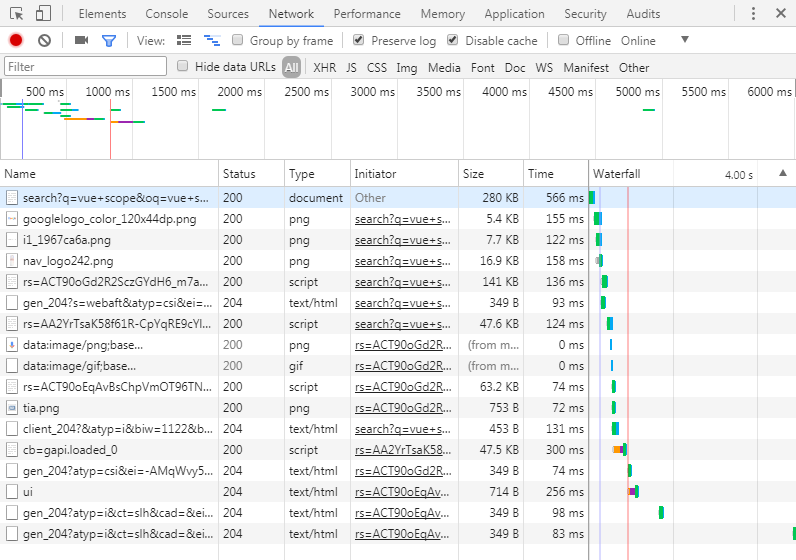
在这里,我们能看到所有浏览器发起的网络请求,包括页面、图片、CSS 文件、XHR 请求等,还能看到请求的状态(200 成功、404 找不到、缓存、重定向等等)、耗时、请求头和内容、返回头和内容,等等等等。这里第一个就是我们的页面请求,返回<html>页面,然后浏览器会加载页面,同时页面中涉及的资源也会触发请求下载,包括我们看到的 png 图片、js 文件,这里没有 css 样式,大概是样式被直出到<html>页面里了。
从浏览器控制台可以看到当前页面的一些网络请求,但无法完整地看到整个请求和渲染的流程。
回到前面的问题,当我们在浏览器输入网页地址,按下回车键后,浏览器的处理过程如下(以 Chrome 为例):
(1) 首先由浏览器进程的 UI 线程进行处理。如果是 URI,UI 线程会发起网络请求来获取网站内容;如果不是,则进入搜索引擎。
(2) 请求过程由网络线程来完成(此处涉及之前提到的 HTTP 请求过程)。如果响应是 HTML 文件,则是将数据传递到渲染器进程;如果是其他文件,则意味着这是下载请求,此时会将数据传递到下载管理器。
(3) 确认浏览器应导航到请求站点后,网络线程通知 UI 线程数据准备就绪。
(4) UI 线程寻找一个渲染器进程来进行网页渲染,数据和渲染器进程都准备好后,HTML 数据通过 IPC 从浏览器进程传递到渲染器进程中。
(5) 渲染器进程接收 HTML 数据后,将开始加载资源并渲染页面。
(6) 渲染器进程完成渲染后,通过 IPC 通知浏览器进程页面已加载。
以上是用户在地址栏输入网站地址,到页面开始渲染的整体过程。如果当前页面跳转到其他网站,浏览器将调用一个单独的渲染进程来处理新导航,同时保留当前渲染进程来处理像unload这类事件。
其中,HTTP 的请求过程如下:
(1) DNS 域名解析(此处涉及 DNS 的寻址过程),找到网页的存放服务器。
(2) 浏览器与服务器建立 TCP 连接。
(3) 浏览器发起 HTTP 请求。
(4) 服务器响应 HTTP 请求,返回相应的资源内容。
# 3. 浏览器渲染机制
我们的浏览器会解析三个东西:
- 渲染引擎解析 HTML/SVG/XHTML 文件,解析这三种文件会产生一个 DOM Tree(DOM 节点树)
- 渲染引擎解析 CSS,会产生 CSS Rule Tree(CSS 规则树)
- JavaScript 解释器解析 Javascript 脚本,Javascript 脚本可以通过 DOM API 和 CSSOM API 来操作 DOM Tree 和 CSS Rule Tree
解析完成后,浏览器引擎会通过 DOM Tree 和 CSS Rule Tree 来构造 Render Tree(渲染树)。在这个过程中,像header或display:none的元素,它们会存在 DOM Tree 中,但不会被添加到 Render Tree 里。大致流程如下图:

渲染的流程基本上如下:
- 解析(Parser):构建渲染树
- 布局(Layout):定位坐标和大小、是否换行、各种
position/overflow/z-index属性等计算 - 绘制(Paint):判断元素渲染层级顺序
- 光栅化(Raster):将计算后的信息转换为屏幕上的像素
渲染的过程中会触发重绘(Repaint)和重排(Reflow):
- 重绘:屏幕的一部分要重画,比如某个 CSS 的背景色变了,但是元素的几何尺寸没有变
- 重排:元素的几何尺寸变了(渲染树的一部分或全部发生了变化),需要重新验证并计算渲染树
为了不对每个小的变化都进行完整的布局计算,渲染器会将更改的元素和它的子元素进行脏位标记,表示该元素需要重新布局。其中,全局样式更改会触发全局布局,部分样式或元素更改会触发增量布局,增量布局是异步完成的,全局布局则会同步触发。
重排需要涉及变更的所有的结点几何尺寸和位置,成本比重绘的成本高得多的多。所以我们要注意以避免频繁地进行增加、删除、修改 DOM 结点、移动 DOM 的位置、Resize 窗口、滚动等操作,因为可能会导致性能降低。
光栅化
通过解析、计算和布局过程,浏览器获得了文档的结构、每个元素的样式、绘制顺序等信息。将这些信息转换为屏幕上的像素,这个过程被称为光栅化。
光栅化可以被 GPU 加速,光栅化后的位图会被存储在 GPU 内存中。根据前面介绍的渲染流程,当页面布局变更了会触发重排和重绘,还需要重新进行光栅化。此时如果页面中有动画,则主线程中过多的计算任务很可能会影响动画的性能。
因此,现代的浏览器通常使用合成的方式,将页面的各个部分分成若干层,分别对其进行栅格化(将它们分割成了不同的瓦片),并通过合成器线程进行页面的合成。过程如下:
(1) 当主线程创建了合成层并确定了绘制顺序,便将这些信息提交给合成线程。
(2) 合成器线程将每个图层栅格化,然后将每个图块发送给光栅线程。
(3) 光栅线程栅格化每个瓦片,并将它们存储在 GPU 内存中。
(4) 合成器线程通过 IPC 提交给浏览器进程,这些合成器帧被发送到 GPU 进程处理,并显示在屏幕上。
合成的真正目的是,在移动合成层的时候不用重新光栅化。因为有了合成器线程,页面才可以独立于主线程进行流畅的滚动。
到此,我们的页面便渲染完成。
# 4. 浏览器加载顺序
览器在加载页面的时候会用到 GUI 渲染线程和 Javascript 引擎线程。GUI 渲染线程负责渲染浏览器界面 HTML 元素,Javascript 引擎线程主要负责处理 Javascript 脚本程序,它们之间是互斥的关系,当 Javascript 引擎执行时 GUI 线程会被挂起。
因此,正常的网页加载流程是这样的:
(1) 浏览器一边下载 HTML 网页,一边开始解析。
(2) 解析过程中,发现<script>标签。
(3) 暂停解析,网页渲染的控制权转交给JavaScript引擎。
(4) 如果<script>标签引用了外部脚本,就下载该脚本,否则就直接执行。
(5) 执行完毕,控制权交还渲染引擎,恢复往下解析 HTML 网页。
以前我们喜欢把外部的 CSS 和 Javascript 文件都集中放在一起,通常会放在<head>里。浏览器需要在解析到<body>标签的时候才开始渲染页面,因此把 Javascript 放在<head>里,意味着必须把所有 Javascript 代码都下载、解析和解释完成后,才能开始渲染页面。
如果外部脚本加载时间很长(比如一直无法完成下载),就会造成网页长时间失去响应,浏览器就会呈现“假死”状态,用户体验会变得很糟糕。因此,我们常常将 Javascript 放在<body>的最后面,可以避免资源阻塞,页面得以迅速展示。当然,我们还可以使用defer/async/preload等属性来标记<script>标签,来控制 Javascript 的加载顺序。
除此之外,浏览器在渲染页面的过程需要解析 HTML、CSS 得到 DOM 树和 CSS 规则树,它们结合才生成最终的渲染树并渲染(该部分内容会在浏览器的加载和渲染流程部分详细介绍)。因此,我们还常常将 CSS 放在<head>里,可用来避免浏览器渲染的重复计算。
# 5. 浏览器缓存
当一个客户端请求 WEB 服务器, 请求的内容可以从以下几个地方获取:服务器、浏览器缓存中或缓存服务器中,这取决于服务器端输出的页面信息。页面文件的三种缓存状态包括:
- 最新的:选择不缓存页面,每次请求时都从服务器获取最新的内容
- 未过期的:在给定的时间内缓存,如果用户刷新或页面过期则去服务器请求,否则将读取本地的缓存,这样可以提高浏览速度
- 过期的:也就是陈旧的页面,当请求这个页面时,必须进行重新获取
浏览器会在第一次请求完服务器后得到响应,我们可以在服务器中设置这些响应,从而达到在以后的请求中尽量减少甚至不从服务器获取资源的目的。浏览器是依靠请求和响应中的的头信息来控制缓存的,包括:
Expires与Cache-ControlExpires和Cache-Control就是服务端用来约定和客户端的有效时间的- 规定如果
max-age和Expires同时存在,前者优先级高于后者 - 若符合,浏览器相应 HTTP200(from cache)
Last-Modified/If-Modified-Since- 当有效期过后,检查服务端文件是否更新的第一种方式,要配合
Cache-Control使用
- 当有效期过后,检查服务端文件是否更新的第一种方式,要配合
ETag/If-None-MatchETag值在服务端和服务端代表该文件唯一的字符串对比(如果服务端该文件改变了,该值就会变)- 如果相同,则响应 HTTP304,从缓存读数据
- 如果不相同,相应 HTTP200,返回更新后的数据,同时通过响应头更新
Last-Modified的值(以备下次对比)
# 5. 浏览器同源政策
同源政策的目的,是为了保证用户信息的安全,防止恶意的网站窃取数据。所谓"同源"指的是"三个相同": 协议相同、域名相同、端口相同。随着互联网的发展,"同源政策"越来越严格。目前,如果非同源,共有三种行为受到限制:Cookie/LocalStorage/IndexDB 无法读取、DOM 无法获得、AJAX 请求不能发送。
常见的跨域解决方案包括:
document.domain + iframe(只有在主域相同的时候才能使用该方法)- 动态创建 script(JSONP)
- JSONP 包含两部分:回调函数和数据
- 回调函数是当响应到来时要放在当前页面被调用的函数
- 数据就是传入回调函数中的 json 数据,也就是回调函数的参数
location.hash + iframe- 原理是利用
location.hash来进行传值
- 原理是利用
window.name + iframe- name 值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值
postMessage(HTML5 中的 XMLHttpRequest Level 2 中的 API)- CORS
- websockets
其中,CORS 作为现在的主流解决方案,需要重点了解。CORS 是一个 W3C 标准,全称是"跨域资源共享"(Cross-origin resource sharing)。它允许浏览器向跨源服务器,发出 XMLHttpRequest 请求,从而克服了 AJAX 只能同源使用的限制。
实现 CORS 通信的关键是服务器,只要服务端实现了 CORS 接口,就可以进行跨源通信。对于简单请求,浏览器直接发出 CORS 请求。具体来说,就是在头信息之中,增加一个Origin字段。
如果Origin指定的域名在许可范围内,服务器返回的响应,会多出几个头信息字段(Access-Control-**等等)。其中,简单请求的要求是:
- 请求方法是以下三种方法之一:
HEAD/GET/POST - HTTP 的头信息不超出以下几种字段:
Accept/Accept-Language/Content-Language/Last-Event-ID/Content-Type(只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain)
不符合以上要求的请求,成为非简单请求。非简答请求会在正式通信之前,增加一次 HTTP 查询请求(请求方法是OPTIONS),称为"预检"请求(preflight)。通过“预检”请求,浏览器会先询问服务器当前域名是否在服务器的许可名单之中,以及可以使用哪些 HTTP 方法和头信息字段。当服务端给予肯定答复,浏览器才会发出正式的 XMLHttpRequest 请求,否则就报错。